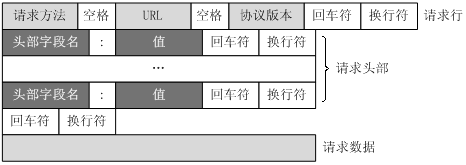
store.js
store.js 用来作为存储session的仓库,它定义了一个Store类,含有sessions和__timer两个map类型的属性,都是通过一个sid获取对应的session和timer。代码如下:
1 | const { randomBytes } = require('crypto'); |
- 构造函数:初始化
sessions和__timer两个map; getID(length):生成给定长度的随机二进制串,转为十六进制字符串后返回,作为session的id;get(sid):通过sid,获取对应的session对象,若sid无效,返回undefined;set(session, { sid = this.getID(24), maxAge } = {}):参数1是一个对象,将被转化为json字符串存入仓库中;参数2是一个对象,使用解构赋值,赋值给sid,maxAge:若参数2的对象没有sid,则会生成一个新的sid,若参数2没有maxAge,则maxAge为undefined, 该session将不会过期。set函数功能为:给传来的sid、或新生成的sid设置一个对应的json对象字符串,存储在sessionsmap中,若maxAge不为空,则给该sid设置一个对应的定时器,maxAge毫秒后执行destroy(sid)函数。若原sid存在,可以重置过期时间。destroy(sid):删除sessions和__timer两个map中,sid对应的项。
koa-session2/index.js
index.js 是koa-session2的入口文件,向外暴露一个函数,参数是一个配置对象,返回一个异步函数async (ctx, next) => {}用作中间件。代码和注释如下:
1 | const Store = require('./libs/store.js'); |
koa-session2使用方法
由上述代码及注释,可以总结出以下几点使用方法:
1. 向app添加koa-session2中间件
将koa-session2中间件添加在其他需要使用session的中间件之前。后端在收到请求时,先通过koa-session2中间件向ctx添加了session属性,然后将控制器交给其他中间件,其他中间件中可以使用ctx.session,最后在其他中间件执行完后回到koa-session2,koa-session2会根据当前状态决定是否给前端发送cookie。
1 | app.use(session({ |
2. 面对前端发送请求的各种情况,后端处理该请求的中间异步函数如何处理能够利用koa-session实现seesion机制?
- 前端请求无对应的cookie(sid)时,分析以下三种情况:
- 进行登录请求:从源码可以看出,当sid不存在时,koa-session2首先会创一个空的session对象,若在其他中间件中修改了
ctx.session导致old != sess或者在其他中间件中调用了ctx.session.refresh()使need_refresh为true,可以使koa-session2继续下面的步骤,为该session创建一个sid,将sid作为cookie返回给前端。一般我们可以在用户无cookie进行登录操作时,验证完用户名、密码后,给ctx.session添加一个username属性,这样既可以时session与用户关联,也能时koa-session2将sid发给前端。 - 进行不需要cookie的请求:由于我们不希望在这里给该请求生成session和cookie,因此要注意在处理该请求时,不能给ctx.session添加属性或调用
ctx.session.refresh()。 - 进行需要cookie的请求:若该请求需要有效身份信息,而前端请求无cookie,则后端返回一个重定向至登录界面即可。如何判断是请求否有对应cookie:(1)可以在处理该请求的异步函数中检查是否有
ctx.cookies.get(key);但可能前端有对应cookie,但该cookie无效,因此推荐方法(2)。(2)检查ctx.session.username是否存在。因为对于一个有效的cookie,我们在之前登录操作中就给该session添加了一个username属性,因此若ctx.session.username不存在,则说明该cookie无效,后端返回一个重定向即可。
- 进行登录请求:从源码可以看出,当sid不存在时,koa-session2首先会创一个空的session对象,若在其他中间件中修改了
- 前端请求对应的cookie(sid)无效时:
- 进行登录请求:由源码可知koa-session2首先根据该无效sid从store中查找session时,发现session为空,则会生成一个新的sid,并且生成一个空的session对象。在经过其他中间件后判断
if(id && !ctx.session),若为真,则koa-session2会删除该session对象,并将前端对应cookie置为空。因此,与情况1.1一样处理即可:验证完用户名、密码后,给ctx.session添加一个username属性。 - 进行不需要cookie的请求:与情况1.2一样,我们不希望在这里给该请求生成session和cookie,因此我们在处理该请求时,不给ctx.session添加属性即可,这样后端会将前端该错误cookie清空。
- 进行需要cookie的请求:与情况1.3一样,检查到
ctx.session.username不存在,则说明cookie无效,返回重定向登录界面即可。
- 进行登录请求:由源码可知koa-session2首先根据该无效sid从store中查找session时,发现session为空,则会生成一个新的sid,并且生成一个空的session对象。在经过其他中间件后判断
前端拥有正确的cookie时:
进行登录操作:有两种处理方式:(1)检查到
ctx.session.username存在,说明cookie正确,返回重定向至主页面即可,前端在请求主页面时,会自动携带cookie,使用对应的身份进行操作。(2)在验证完用户名和密码后,先将ctx.session置为空对象,再给ctx.session添加一个username属性。无论ctx.session是否与原先相同,后端是否发送cookie给前端,前端存的都是原来的cookie,而此cookie就是现在登录的用户对应session的sid。总结:推荐方法(2),因为方法二可以处理登录新用户的情况,这样在登录新用户的同时相对于登出了原用户;且方法(2)处理登录请求时无需加额外条件判断,无论前端是否携带cookie,均先将ctx.session置为空对象,再给ctx.session添加一个username属性即可。因为若请求未携带cookie,则ctx.session本身就只含一个refresh函数,且在回到koa-session2后首先会将refresh从ctx.session中清除,先将ctx.session置为空对象并无影响。进行登出操作:根据以下源码可知,当在其他中间件中将
ctx.session置为空对象时,回到koa-session2后,koa-session2会自动删除store中存储的对应session,并且会将前端对应cookie置空,因此直接执行ctx.session = {}即可实现登出。1
2
3
4
5
6
7
8
9
10
11
12
13// if is an empty object
if(sess == '{}') {
ctx.session = null;
}
//若id存在,且现在session为空,
//则在store中删除该id对应session和timer,且给前端设置cookie key的值为空
// need clear old session
if(id && !ctx.session) {
await store.destroy(id, ctx);
ctx.cookies.set(key, null);
return;
}
- 进行其他请求时,根据用户身份进行相应的逻辑处理即可。
3. 总结后端请求处理函数的处理方法
- 登录:验证用户名密码成功后,执行
ctx.session = {username: <username>}即可,否则返回登录失败。 - 登出:验证
ctx.session.username存在后,说明已经是登录状态,执行ctx.session = {}即可。 - 需要正确cookie的请求:若
ctx.session.username不存在,则返回重定向至登录界面(注:若为xhr请求,前端收到重定向后要自行处理进行页面跳转);否则,可以根据ctx.session.username,得到用户身份进行正常请求处理,可以向ctx.session添加其他属性存储会话信息。 - 不需要cookie的请求:注意不要修改
ctx.session或调用ctx.session.refresh()即可。